Chorus
Chorus
Эффект Chorus имитирует несколько одновременно играющих инструментов или голосов, добавляя несколько коротких задержек с небольшим количеством обратной связи. В результате получается более насыщенный и богатый звук. Вы можете использовать хорус для расширения вокального трека или для добавления стерео простора моно звуку. Вы также можете использовать его для создания интересных спецэффектов.
В Adobe Audition применяется метод прямого моделирования эффекта хоруса: из каждого исходного голоса формируются новые голоса, звучание которых отличается от оригинала за счет неглубокой модуляции высоты тона и сдвига сигнала во времени, а также за счет случайного интонирования и вибрато. Пространственную протяженность и даже некоторую объемность эффекту придает наличие обратной связи.
Для достижения наилучшего результата с моно файлами, конвертируйте их в стерео перед применением эффекта Chorus.
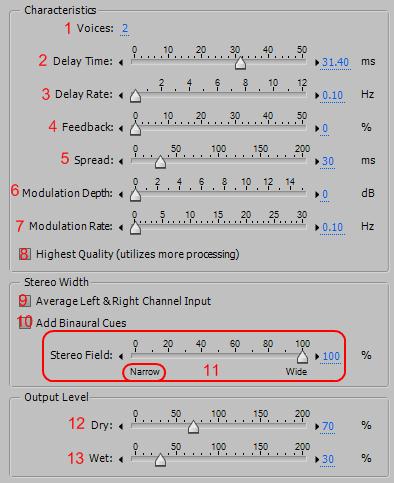
1. Voices (голоса) — количество голосов, участвующих в формировании эффекта Chorus. При добавлении большего количества голосов звук становится богаче, но увеличиваться нагрузка на процессор.
2. Delay Time (время задержки) — максимальное временное рассогласование (задержки) голосов. Рекомендуется устанавливать этот параметр в пределах 15–35 мс. Если установлено очень низкое значение, то все голоса начнут сливаться с оригиналом, и может возникнуть неестественный эффект, напоминающий флэнжер. При слишком больших значениях параметра вам может показаться, что запись воспроизводится магнитофоном, который начал "зажевывать" ленту.
3. Delay Rate (скорость задержки) — частота модуляции задержки. Определяет время требуемое, для того чтобы цикл задержек изменился от нуля до максимального значения. Поскольку фактические задержки изменяются с течением времени, а также высота тона сэмпла увеличивается или уменьшается с течением времени, каждый голос размещается немного не в ладу с другими (давая эффект отдельных голосов). Например, значение 2 Гц будет варьировать задержки от нуля до максимума и обратно два раза в секунду (имитируя вибрато высоты тона два раза в секунду). Если значение этого параметра слишком низкое, высота тона отдельных голосов изменяется незначительно. Если значение слишком высокое, голоса могут изменяться так быстро, что может возникнуть эффект трели.
4. Feedback (обратная связь) — определяет процент обработанных голосов подаваемых обратно на вход. Обратная связь может придать сигналу дополнительное эхо или эффект реверберации. Низкие значения Feedback, менее 10 % могут дополнительно обогатить звук, в зависимости от Delay Time (2) и настроек вибрато. Высокие значения дают более традиционную обратную связь, громкий звон, который может быть достаточно сильным, что сигнал начнет клиппировать.
5. Spread (распределение) — дополнительная задержка каждого голоса, голоса распределяются по времени в диапазоне 200 миллисекунд (1/5 доли секунды). Высокие значения данного параметра разделяют голоса так что они начинают звучать в разное время, чем выше значение, тем дальше друг от друга начнут звучать голоса. Малые значения заставляют звучать голоса в унисон. В зависимости от настроек других параметров, низкие значения Spread могут привести к появлению эффекта флэнжера, данный эффект может быть нежелательным если вы хотите имитировать хор.
6. Modulation Depth (глубина модуляции) — определяет максимальное отклонение по амплитуде (глубина вибрато). Например, вы можете изменять амплитуду голосов хоруса так, что разница их громкостей будет изменять на 5 дБ громче или тише, чем оригинал. При очень малых значениях (менее 1 дБ), глубина отклонения может быть незаметной, если Modulation Rate (7) имеет слишком большое значение. При очень высоких значениях, звук может стать тише, создавая нежелательную трель. Естественное вибрато возникает при значениях в диапазоне от 2 дБ до 5 дБ.
7. Modulation Rate (скорость модуляции) — определяет максимальную скорость, с которой происходят изменения амплитуды (частота вибрато). При очень низких значениях, громкость звучания голоса изменяется постепенно (громкость становится то громче, то тише), как у певицы, которая не может держать его, или ее дыхание не устойчивое. При очень высоких значениях, результат может быть нервным и неестественным.
8. Highest Quality (наивысшее качество) — обеспечивает наивысшее качество обработки. Повышение качества увеличивает время обработки для предпрослушки полученного эффекта перед применением.
9. Average Left & Right Channel Input (средний, левый и правый входные каналы) — если флажок снят, то исходные сигналы левого и правого каналов будут обрабатываться эффектом по отдельности, для сохранения стерео изображения. Существовавший до обработки стерео образ звука претерпит минимальные искажения. Если обрабатывается монофонический файл, то флажок следует снять, чтобы избежать бессмысленной траты времени на преобразование моно сигнала в моно сигнал.
10. Add Binaural Cues (добавить бинауральные иллюзии) — при установленном флажке в сформированный сигнал добавляются задержки, разные для правого и левого каналов. В таком случае при прослушивании в наушниках будет в впечатление что голоса исходят из различных точек панорамы. Если фонограмму предполагается прослушивать через стерео наушники, флажок рекомендуется установить. Снять его следует, если не исключено воспроизведение фонограммы через колонки.
11. Stereo Field slider (слайдер стерео поля) — предназначен для выбора протяженности эффекта по стерео панораме (ширины стерео поля). Если ползунок находится в положении Narrow (введено число 0), все голоса будут помещены в центр стерео панорамы. При установке ползунка в положение 50 % все голоса расположатся по панораме равномерно слева направо. Например, если имитируется хор из пяти голосов, то голоса панорамируются, т. е. находятся:
Первый голос — в крайней левой точке панорамы.
Второй голос — посредине левой части панорамы.
Третий голос — в центре панорамы.
Четвертый голос — посредине правой части панорамы.
Пятый голос — в крайней правой точке панорамы.
Если для параметра, определяющего протяженность стереоэффекта, выбирать значения больше 50 %, то по мере перемещения ползунка вправо голоса начнут перемещаться к крайним точкам панорамы: "левые" голоса переместятся еще левее, а "правые" — правее. Если вы работаете с нечетным числом голосов, то в таком случае один голос будет всегда находиться точно в центре панорамы. При четном числе голосов в центре нет ни одного голоса. Одна половина голосов сосредоточена в правой части панорамы, другая — в левой.
12. Dry (сухой) — уровень сухого сигнала (не обработанного эффектом).
13. Wet (мокрый) — уровень обработанного звука эффектом.